PyTorchを使って転移学習をする方法について解説【2行でモデルを読み込めます】

こんにちは。フリーランスエンジニアのmasakiです。
今回は、PyTorchを使って転移学習をする方法について解説します。
この記事の対象読者は以下のような方になります。
- Pythonやディープラーニングの基本はわかる方
- PyTorchでの転移学習を体験してみたい方
- 転移学習とは何か知りたい方
それでは解説していきます。
転移学習とは?
転移学習とは、事前に学習済みのモデルのパラメータのうち、入力に近い部分は全て固定し、出力に近い部分のパラメータのみを更新する学習方法です。
転移学習を使えば、既存のモデルを使って別の問題にサクッと応用できます。
ちなみに、転移学習とよく比較されるものにファインチューニングというものもありますが、こちらは事前に学習済みのモデルのパラメータを全て更新する学習方法になります。
これら2つの手法は、一般的には以下のような使い分けになっています。
- 転移学習:学習データが少ない場合
- ファインチューニング:学習データが多い場合
目次
- PyTorchを使って転移学習をする方法
- 事前学習済みモデルの使い方
- ソースコードの全体像
PyTorchを使って転移学習をする方法
PyTorchを使って転移学習をするのは比較的簡単です。
なぜなら、PyTorchには事前学習済みモデルがたくさん用意されているからです。
以下はPyTorchの公式ドキュメントですが、AlexNetやVGG19などのモデルが用意されているのがわかります。
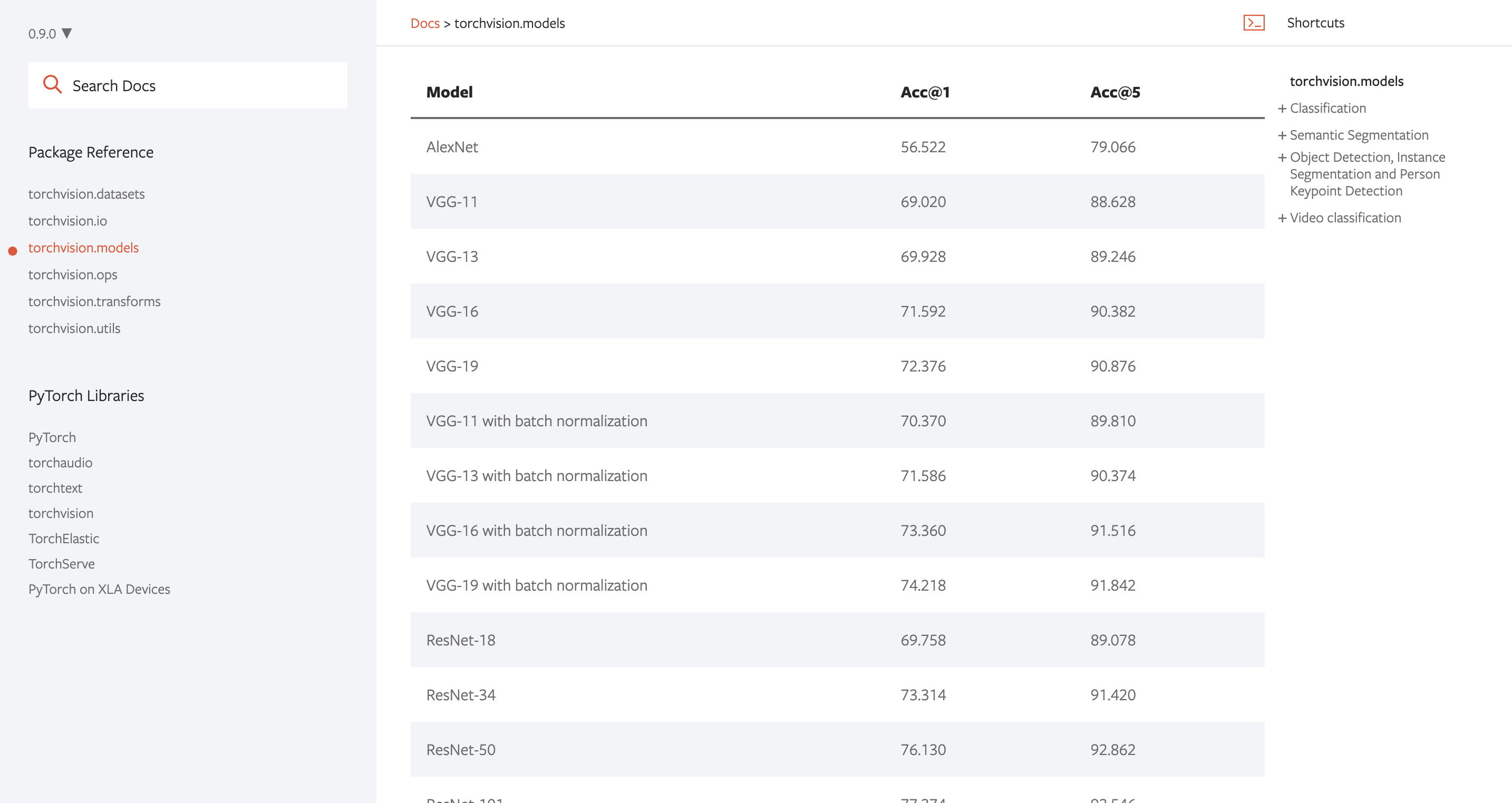
事前学習済みモデルの使い方
では、上記のモデルをどのように取り込めば良いのでしょうか?
やり方はめちゃくちゃ簡単で、以下のドキュメントのとおり。

要は、以下のようにインポート文を書いて、使いたいモデルをインスタンス生成するだけでOKです。
今回はAlexNetを使ってみます。
import torchvision.models as models
alexnet = models.alexnet()このように、たった2行で事前学習済みモデルを呼び出せてしまいます。最高ですね。
ちなみにこの辺りはkerasと似ています。
次はこのモデルを、自身の扱う問題に適用していきます。
今回は、事前学習済みのAlexNetのモデルを転移学習させ、CIFAR-10のデータセットを分類していきたいと思います。
CIFAR-10とは
CIFAR-10とは、1枚が32px × 32pxのカラー画像のデータセットです。
画像は訓練用が5万枚、テスト用が1万枚あり、飛行機、犬、馬などの10種類のカテゴリのどれかに分類されます。

なので、今回は10分類の問題になるということです。
よって多分類問題を扱います。
転移学習をする上での注意点
転移学習をする上での注意点として、出力層の調整が必要です。
事前に用意されているAlexNetでは、出力の形状が1000となっています。(下の赤枠部分のout_featuresが出力の形状です。)
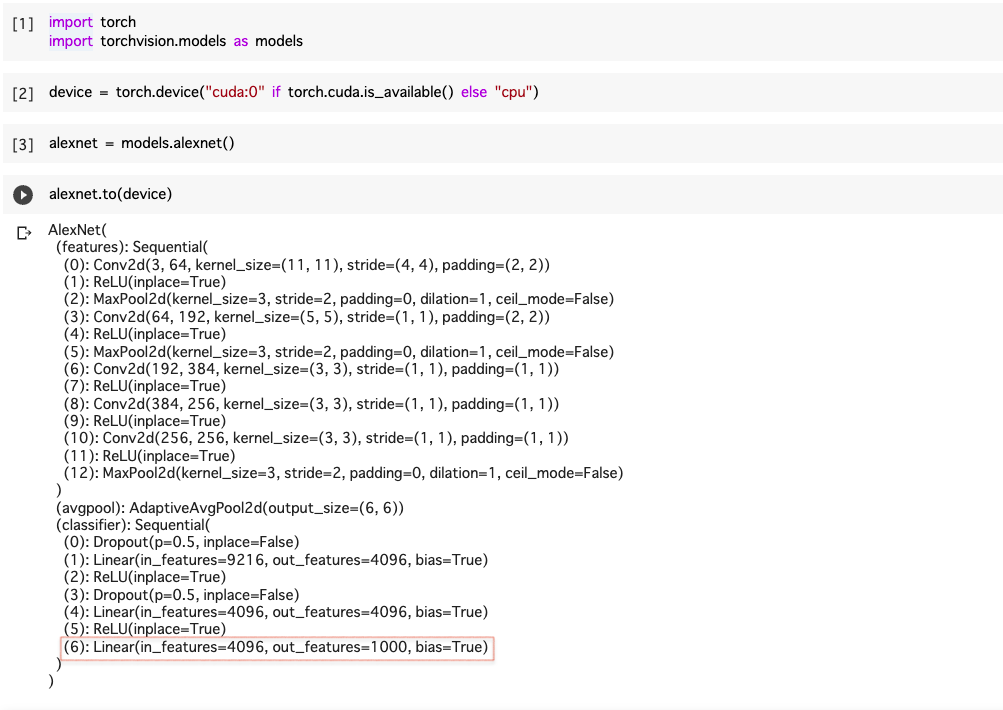
今回は10分類なので、ここを10に変更しなければなりません。
出力層はfcというプロパティに格納されているので、ここを以下のように修正します。
import torch.nn as nn
alexnet.fc = nn.Linear(4096, 10)in_featuresの値はそのままで、out_featuresの値だけ10に変更して上書きすればOKです。
ソースコードの全体像
僕はGoogle ColabのGPUを使ってソースコードを動かしました。
Google ColabでのGPUの使い方について知りたい方は、以下の記事を先にご覧ください。
» Google ColabのGPU上で、PyTorchで実装したディープラーニングを動かしてみた【コピペで体験可能】
※この記事では転移学習を体験してもらうことを目的としているので、ソースコードの詳細については説明していません。
そちらを知りたい方は、『最短コースでわかる PyTorch&深層学習プログラミング』を参考にして頂くと良いかと思います。
それでは、以下がソースコードの全体像になります。
コピペすれば動くようになっているので、PyTorchでの転移学習を是非とも体験してみてください。
!pip install japanize_matplotlib | tail -n 1
!pip install torchviz | tail -n 1
!pip install torchinfo | tail -n 1
%matplotlib inline
import numpy as np
import matplotlib.pyplot as plt
import japanize_matplotlib
from IPython.display import display
import torch
import torch.nn as nn
import torchvision.models as models
import torch.optim as optim
from torchinfo import summary
from torchviz import make_dot
import torchvision.transforms as transforms
from torch.utils.data import Dataset, DataLoader
import torchvision.datasets as datasets
device = torch.device("cuda:0" if torch.cuda.is_available() else "cpu")
def eval_loss(loader, device, net, criterion):
# データローダーから最初の1セットを取得する
for images, labels in loader:
break
# デバイスの割り当て
inputs = images.to(device)
labels = labels.to(device)
# 予測計算
outputs = net(inputs)
# 損失計算
loss = criterion(outputs, labels)
return loss
# 学習用関数
def fit(net, optimizer, criterion, num_epochs, train_loader, test_loader, device, history):
# tqdmライブラリのインポート
from tqdm.notebook import tqdm
base_epochs = len(history)
for epoch in range(base_epochs, num_epochs+base_epochs):
train_loss = 0
train_acc = 0
val_loss = 0
val_acc = 0
#訓練フェーズ
net.train()
count = 0
for inputs, labels in tqdm(train_loader):
count += len(labels)
inputs = inputs.to(device)
labels = labels.to(device)
# 勾配の初期化
optimizer.zero_grad()
# 予測計算
outputs = net(inputs)
# 損失計算
loss = criterion(outputs, labels)
train_loss += loss.item()
# 勾配計算
loss.backward()
# パラメータ修正
optimizer.step()
# 予測値算出
predicted = torch.max(outputs, 1)[1]
# 正解件数算出
train_acc += (predicted == labels).sum().item()
# 損失と精度の計算
avg_train_loss = train_loss / count
avg_train_acc = train_acc / count
#予測フェーズ
net.eval()
count = 0
for inputs, labels in test_loader:
count += len(labels)
inputs = inputs.to(device)
labels = labels.to(device)
# 予測計算
outputs = net(inputs)
# 損失計算
loss = criterion(outputs, labels)
val_loss += loss.item()
# 予測値算出
predicted = torch.max(outputs, 1)[1]
# 正解件数算出
val_acc += (predicted == labels).sum().item()
# 損失と精度の計算
avg_val_loss = val_loss / count
avg_val_acc = val_acc / count
print (f'Epoch [{(epoch+1)}/{num_epochs+base_epochs}], loss: {avg_train_loss:.5f} acc: {avg_train_acc:.5f} val_loss: {avg_val_loss:.5f}, val_acc: {avg_val_acc:.5f}')
item = np.array([epoch+1, avg_train_loss, avg_train_acc, avg_val_loss, avg_val_acc])
history = np.vstack((history, item))
return history
# 学習ログ解析
def evaluate_history(history):
#損失と精度の確認
print(f'初期状態: 損失: {history[0,3]:.5f} 精度: {history[0,4]:.5f}')
print(f'最終状態: 損失: {history[-1,3]:.5f} 精度: {history[-1,4]:.5f}' )
num_epochs = len(history)
unit = num_epochs / 10
# 学習曲線の表示 (損失)
plt.figure(figsize=(9,8))
plt.plot(history[:,0], history[:,1], 'b', label='訓練')
plt.plot(history[:,0], history[:,3], 'k', label='検証')
plt.xticks(np.arange(0,num_epochs+1, unit))
plt.xlabel('繰り返し回数')
plt.ylabel('損失')
plt.title('学習曲線(損失)')
plt.legend()
plt.show()
# 学習曲線の表示 (精度)
plt.figure(figsize=(9,8))
plt.plot(history[:,0], history[:,2], 'b', label='訓練')
plt.plot(history[:,0], history[:,4], 'k', label='検証')
plt.xticks(np.arange(0,num_epochs+1,unit))
plt.xlabel('繰り返し回数')
plt.ylabel('精度')
plt.title('学習曲線(精度)')
plt.legend()
plt.show()
# イメージとラベル表示
def show_images_labels(loader, classes, net, device):
# データローダーから最初の1セットを取得する
for images, labels in loader:
break
# 表示数は50個とバッチサイズのうち小さい方
n_size = min(len(images), 50)
if net is not None:
# デバイスの割り当て
inputs = images.to(device)
labels = labels.to(device)
# 予測計算
outputs = net(inputs)
predicted = torch.max(outputs,1)[1]
#images = images.to('cpu')
# 最初のn_size個の表示
plt.figure(figsize=(20, 15))
for i in range(n_size):
ax = plt.subplot(5, 10, i + 1)
label_name = classes[labels[i]]
# netがNoneでない場合は、予測結果もタイトルに表示する
if net is not None:
predicted_name = classes[predicted[i]]
# 正解かどうかで色分けをする
if label_name == predicted_name:
c = 'k'
else:
c = 'b'
ax.set_title(label_name + ':' + predicted_name, c=c, fontsize=20)
# netがNoneの場合は、正解ラベルのみ表示
else:
ax.set_title(label_name, fontsize=20)
# TensorをNumPyに変換
image_np = images[i].numpy().copy()
# 軸の順番変更 (channel, row, column) -> (row, column, channel)
img = np.transpose(image_np, (1, 2, 0))
# 値の範囲を[-1, 1] -> [0, 1]に戻す
img = (img + 1)/2
# 結果表示
plt.imshow(img)
ax.set_axis_off()
plt.show()
# PyTorch乱数固定用
def torch_seed(seed=123):
torch.manual_seed(seed)
torch.cuda.manual_seed(seed)
torch.backends.cudnn.deterministic = True
torch.use_deterministic_algorithms = True
# Transformsの定義
# 学習データ用: 正規化に追加で反転とRandomErasingを実施
transform_train = transforms.Compose([
transforms.Resize(112),
transforms.RandomHorizontalFlip(p=0.5),
transforms.ToTensor(),
transforms.Normalize(0.5, 0.5),
transforms.RandomErasing(p=0.5, scale=(0.02, 0.33), ratio=(0.3, 3.3), value=0, inplace=False)
])
# 検証データ用 : 正規化のみ実施
transform = transforms.Compose([
transforms.Resize(112),
transforms.ToTensor(),
transforms.Normalize(0.5, 0.5)
])
# データ取得用関数 Dataset
data_root = './data'
train_set = datasets.CIFAR10(
root = data_root, train = True,
download = True, transform = transform_train)
# 検証データの取得
test_set = datasets.CIFAR10(
root = data_root, train = False,
download = True, transform = transform)
# バッチサイズ指定
batch_size = 50
# データローダー
# 訓練用データローダー
# 訓練用なので、シャッフルをかける
train_loader = DataLoader(train_set, batch_size=batch_size, shuffle=True)
# 検証用データローダー
# 検証時にシャッフルは不要
test_loader = DataLoader(test_set, batch_size=batch_size, shuffle=False)
torch_seed()
alexnet = models.alexnet(pretrained = True)
alexnet.fc = nn.Linear(4096, 10)
alexnet = alexnet.to(device)
lr = 0.001
criterion = nn.CrossEntropyLoss()
optimizer = optim.SGD(alexnet.parameters(), lr=lr, momentum=0.9)
history = np.zeros((0, 5))
num_epochs = 5
history = fit(alexnet, optimizer, criterion, num_epochs,
train_loader, test_loader, device, history)
evaluate_history(history)
classes = ('plane', 'car', 'bird', 'cat',
'deer', 'dog', 'frog', 'horse', 'ship', 'truck')
show_images_labels(test_loader, classes, alexnet, device)ちょっとだけ補足をしておくと、上記のソースコードでは、事前学習済みのモデルをインスタンス生成するときに
alexnet = models.alexnet(pretrained = True)としています。
pretrained = Trueってなんだろう?と思いますよね。
これは、事前に学習した際のパラメータを使うかどうかのフラグです。
今回は、事前に学習した時のパラメータを使いたいのでもちろんTrueにします。
デフォルトではFalseなので、何も設定しなければFalseになります。
コードを実行した時の予測結果として、7割~8割くらいの精度は得られたのではないでしょうか。
おそらく、以下のような感じでかなりの確率で正しく予測できると思います。

最後に
いかがだったでしょうか。
今回の記事で転移学習を一通り体感できたと思うので、次はご自身で用意したデータセットに置き換えて色々試してみるのも面白いかもしれませんね。
参考
今回載せたソースコードは、以下の書籍を参考にしています。
『最短コースでわかる PyTorch&深層学習プログラミング』
![]()